
4.20.26
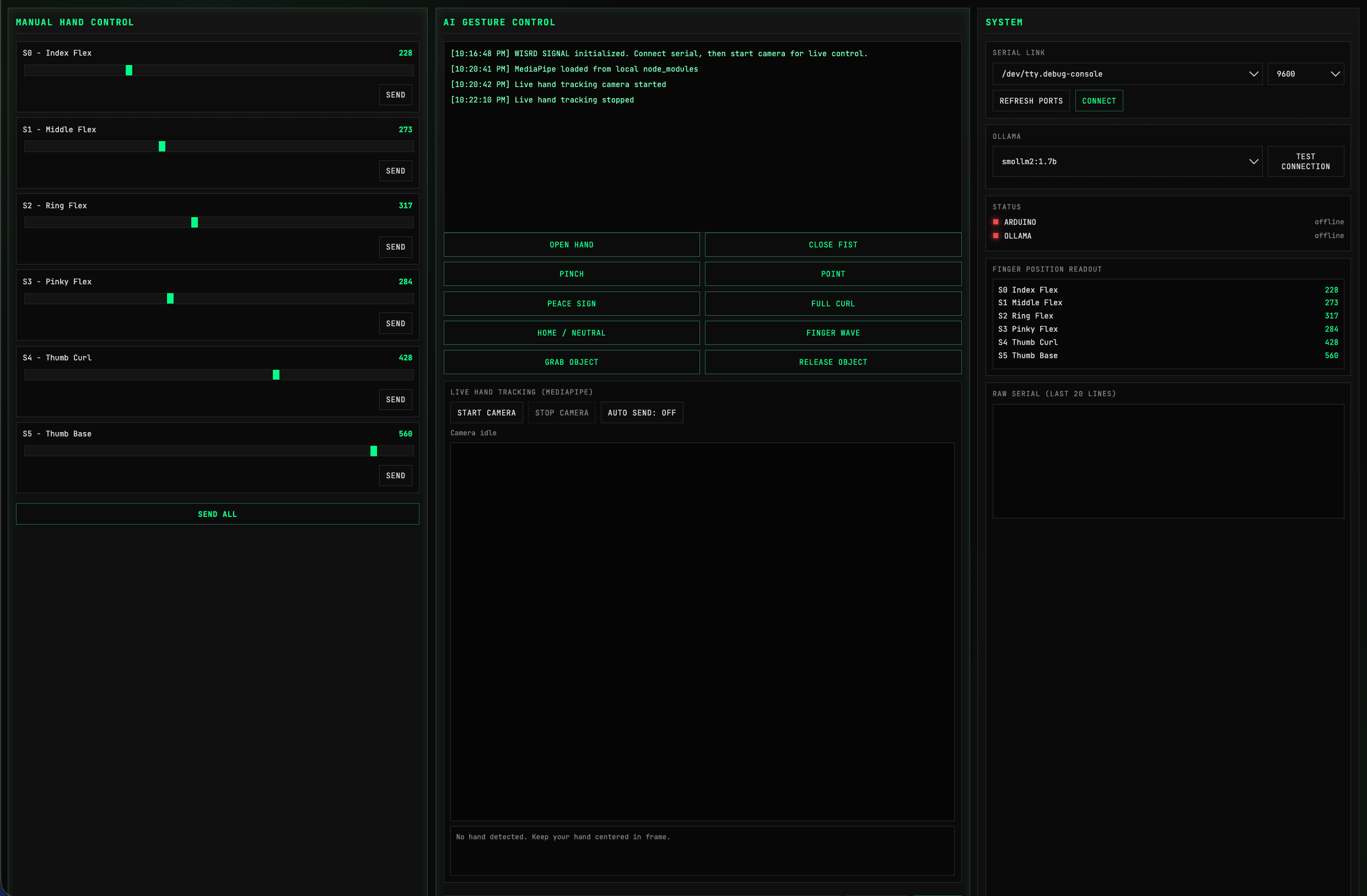
I have figured out that the insight lab 2 essay arm did not yield a high enough data power to effectively asses the data. If possible I will reflect on this either in a poster or after poster session. Other poster from the other various labs are chugging a long and I expect them to yield a positive reaction. Bob an I have been talking about ways to use Qskit from IBM, give we do not do much financial modeling here in WISRD I don’t know how we may be able to utilize it yet. Finally Next to our journal today is a photo of the condensed UI for SIGNAL.
Best,
Guy
4.15.26
Ok I have caved and built a local UI for Chop-Bench after all the missed guesses and horrible rebuilding it works now. I have also gotten Ollama working on Ivan’s App which I have named Servo Interface for Gesture And Language (SIGNAL). I achieved this by upgrading the model and centralizing the structure so the llm output goes through the normalization algorithm pre command string like the other sources. The diagram to the right is indicative of the previous solution and will be updated either on the poster (should it appear there), or otherwise be updated here.
Best,
Guy
3.24.26
I got the funding approved for Chop-Bench my Gen AI benchmarking tool, to test over the break, the CLI is getting very annoying to work with through.
See you after break!
Guy
3.16.26
All projects still on-track, had a brainwave over the weekend and figured out we could use Google Mediapipe to recognize how a hand moves for Ivan’s project. I set it up and it works great. Here is a diagram of how the system works now.
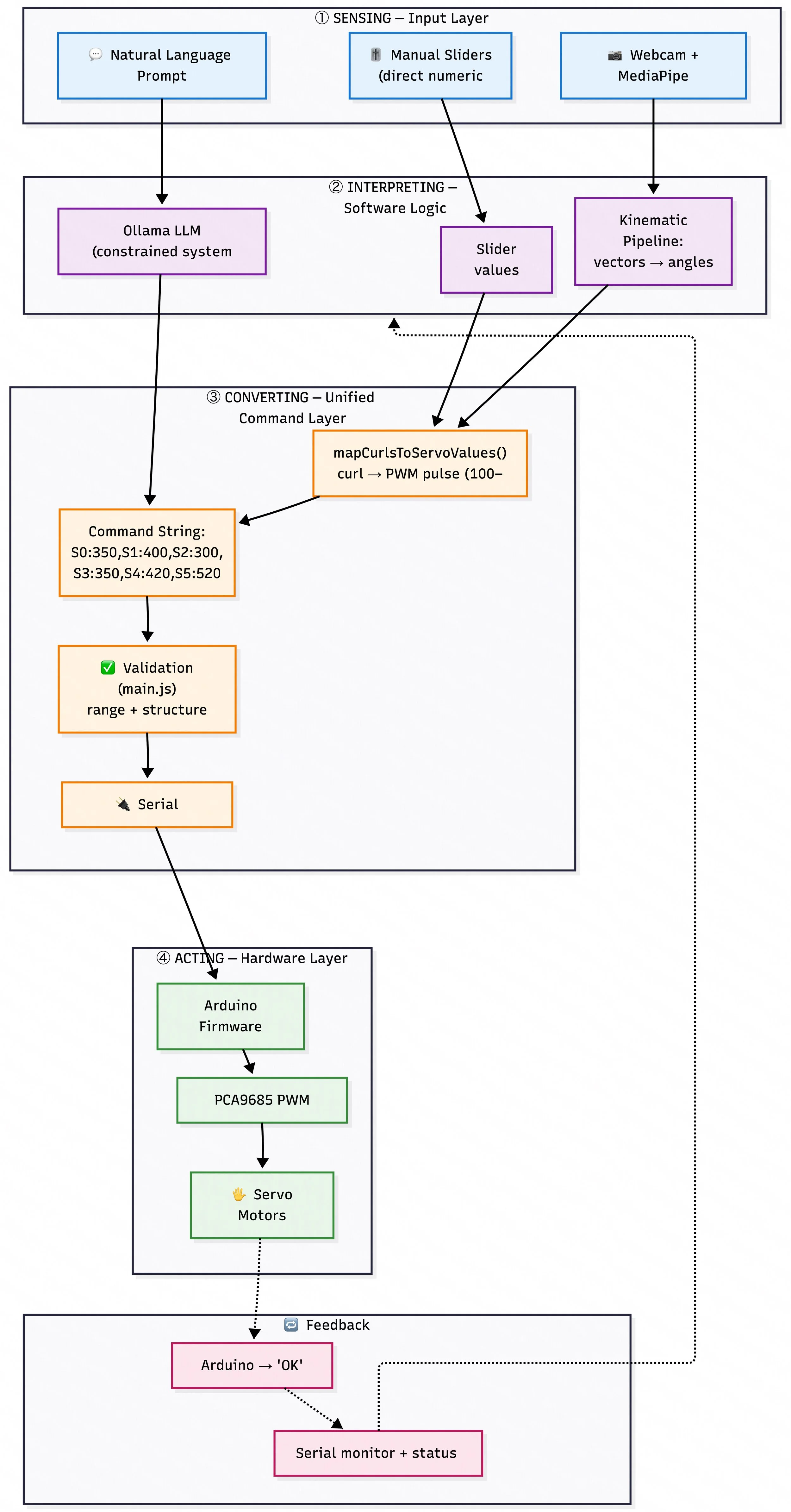
3.10.26
I have been working with Ivan S. to build an interface for his robotic arm. I don’t know what he plans to do with it, but I build an Electron app and gave it a basic UI with presets and, he wants AI, i don’t know becuase Ollama isn’t working great right now.
3.2.26
Austin is now the primary manager of the web scraper project. As we rapidly move towards production aswell as draft 2 of both of our new benchmarking tools; which we will share as soon as we can build out the formal manifests. It became clear that we had the capacity to handle more work. I am incredibly proud of the work all of my techs have done this year and continue to do Independently and in collaboration with other WISRDs and Apprentices.
All the Best,
Guy
2.23.26
As we continue To build the web scraper project We are shifting away from Wordpress though we appreciate the standardization we can no longer continue all our goals with PHP. This was not a decision we took lightly and it will be a lot of work to transition the project to typescript, but it had to be done. In better news continued interest from institution analysts regarding INSIGHT data analysis means we fully expect the data to be processed in time for poster session.
All the Best,
Guy
2.9.26
Sorry for the Gap in journaling it has been an incredibly busy time in the labs. We have begun in earnest using AI coding assist in the web scraper project as we realized in discussions with a stakeholder that not only could progress increase, but given the idea is that the website should be a legible to LLMs as possible this may even get us closer to our goal.
All the Best,
Guy
1.12.26
HNY! This year we will operationalize the projects we began last year. We will build the panel that assesses the phase 1 studies. We will launch the website to begin crawler testing.
Non specific advice from other WISRDs:
Plan ahead.
Set mini due dates and goals for where you want to be in your project
I would advise people to work on their journal for at least 10 mins every week.
All the Best,
Guy
12.12.25
I missed Poster session, I was at the National Association of Independent Schools (NAIS) student conference about AI. I am incredibly sorry miss poster session but I hear it went splendidly and got a full download from the team on the feedback and it sounded great. It was also incredible to go and talk to so many passionate teens about AI and how we use it both in our daily lives and here in WISRD. There are so many learnings I will share with WISRD and will bring up in this journal when they come up as a teaching moment. Until next time!
All the Best,
Guy
12.5.25
Today is poster session, Below are the sources of Error for Assessment of Influence From Research Tools on Writing & Consumer Snack Preference:
Differential typing speed and writing ability could confound productivity measurements
Participants' prior knowledge of the essay topic may vary, affecting both research needs and output quality, however this issue has been theoretically mitigated by randomized topics primarily to do with matters unfamiliar to high schoolers.
Participants may have different levels of investment in the task
Fatigue effects could vary across participants, especially given the dual task design (essay plus snack ranking)
Time pressure may affect participants differently based on individual stress tolerance
Participants may not strictly adhere to the prohibition on external writing tools
Some participants might access personal accounts despite instructions
Verification of private browsing mode usage may be incomplete or inconsistent.
Search engines may have fundamentally different capabilities (e.g., integrated AI features vary significantly across platforms)
Algorithm differences may make certain topics easier to research on specific engines
Search result quality may vary by topic domain rather than engine quality generally
Burner accounts may have different "trust levels" or search histories than typical user accounts
Search engine updates or changes during the study period could affect different groups differently
Teacher panel members may have different interpretations of the rubric despite standardization
Grader fatigue or order effects if essays are evaluated sequentially
The choice between median and mean for final scores may produce different results
Interrater reliability may be insufficient depending on the number of evaluators
Word count does not account for content density or quality of writing
Participants may prioritize length over quality if they perceive word count as the primary metric
Copy/pasting from sources (even if cited) could inflate word counts without reflecting genuine productivity
Topics may be inherently easier or harder to research depending on source availability
The snack preference ranking task, while brief, may create cognitive interference or time pressure that affects essay performance
Participants may rush the essay to ensure completion of both tasks
The fixed 60 minute limit may not allow sufficient time to observe true differences in research efficiency
Some participants may finish early while others feel rushed, creating artificial productivity differences
No baseline assessment of writing ability before the experiment
Environmental conditions (noise, distractions, computer performance) may vary across participants
Time of day effects not controlled
Small sample sizes increase vulnerability to outliers
Conducting multiple statistical tests (ANOVA, correlations) without adjustment increases Type I error probability
Essay scores may not be normally distributed, violating ANOVA assumptions
Correlation analyses may be influenced by restricted range if most essays score similarly
Laboratory research conditions differ from how people naturally use search engines
The prohibition on writing tools doesn't reflect real world research practices
Forced random assignment prevents self selection based on user preference and expertise
Participants may have varying levels of prior experience with their assigned search engine, creating performance differences unrelated to the engine itself
11.21.25
Testing has concluded for the break, with a total of 15 participating the entirety of the trial. I am currently on the way to a leadership retreat so this update will be short however this data will be processed and at least some portion of it will be published in the poster published on December 5th.
All the best,
Guy
11.18.25
Below is the current draft of the abstract for the Gen AI lab’s poster, as always the INSIGHT team is also working hard as testing will begin on Thursday however given the nature of the procedure we still can not share it publicly.
The rapid advancement of Generative Artificial Intelligence, particularly Large Language Models (LLMs), has intensified concerns regarding data collection practices. LLMs are typically trained on vast datasets comprising trillions of data points, often sourced without explicit permission from content creators. This training process inherently produces models with temporal knowledge gaps, prompting AI developers to implement real-time web searching capabilities that effectively bypass original content providers. While ethical web scraping should adhere to website operators' guidelines (robots.txt protocols), evidence suggests certain AI companies may be facilitating practices that some claim constitute intellectual property infringement. This research addresses the critical need to systematically evaluate compliance levels across different AI models, scrapers and companies regarding established web scraping guidelines. By developing a methodology to quantify adherence to data collection protocols, our study aims to provide empirical evidence on the current state of ethical data harvesting in AI development and inform regulatory frameworks governing these practices.
All the best,
Guy
10.27.25
Dear Reader,
This was an interesting set of days. On Wednesday we had dark matter day, if you see any picture from there, chances are I took them. I met with my various labs, and given the early poster session this year we have an even more accelerated first semester timeline. Gen Ai should be set up to collect data by mid September, Recon is already busy as a bee, Cosmic ray is now the biggest lab and hyper productive, Dash has been moving along bioinformatics nicely we just got approval to offer volunteer hours to our test subjects and have amended the procedure to allow for an even bigger sample size, we hope to begin testing in early November and continue through the end of the semester. Now the browser segment, tbc’s Dia got agent mode, but more newsworthy is that OpenAI released ChatGPT atlas, another Chromium but with an AI browser that feels so much like a comet it’s not even funny. Hot Take: this isn’t OpenAI trying to kill chrome or take on google, just trying new ways to use Codex and look for the best ways to interact with AI systems, and obviously harvest data. Pictures from poster session to come,
All the best,
Guy
10.15.25
Dear Reader,
It has been an Interesting week to say the least, some great progress has been made in the past couple days regarding, all labs, more research on all fronts including a Failed Recon occultation due to faulty equipment, more website research, bioinformatics research, among others. I will explain more about the bioinformatics research very soon. Hint: it has to do with the spate of browsers I mentioned a few weeks ago. In my fun personal noteof the post I was looking through my old computer files and found the first poster I ever had a hand in, it is from 2019-2020. Though I had forgotten about it, it is probably the reason I started off doing microbiology, when I was first a WISRD associate in 2022. The Magnitude.io Exolab 6/Tangolab Mission 13 studied The Effect of Microgravity on Nitrogen Fixing Bacteria. Now the only reason we 4th graders. Were involved in the way were was because our science teacher happened to be the head of education programing for Magnitude which sold kits to schools to help them build Curriculum around understanding the characteristics of plants. Either way it’s a fun thing to share. In such a hapless week.
All the best,
Guy

10.6.25
The end of an Era (In the best possible way!)
For almost a decade WISRD members have been exploring AR, VR, Metaverse, or XR. However, after renewed interest in 2023 after the announcement of the Apple Vision Pro, it has become increasingly evident that the field of consumer Integrated Visual Augmentation has advanced to the stage that WISRD can no longer meaningfully add directly to the technical field. Make no mistake, WISRD has overseen and tracked great advancement in the field going from the first Oculus, and Hololens all the way through to the Apple Vision Pro. Given our rapidly aging inventory and despite limited renewed interest by some WISRD members Megan, Matt and myself have decided to sunset the dedicated WISRD XR Lab. This does not mean that WISRD still won’t use XR products in work or research, it just means how we do it is changing. WIE will take a large amount of our legacy equipment, they are the continuation of the XR lab, their purpose is commercial exploration, the other side of the same coin as WISRD and we look forward to working with them on how to best utilize XR and are already in talks for further shared CapEx on the technology. The other XR assets will be nominally managed by INSIGHT however will be effectively generalised WISRD inventory until they are retired from that as well. We are excited for the collaborative future of XR in WISRD with our wonderful partners at WIE and the opportunities and insight they will provide! Thank you to all the people who have worked on XR over the years, Guy G: 2023-2025, Marley Z.: 2021-2023, Max V: 2021-2022, Will S: 2021-2022, Jack C: 2021-2022, Remy: 2016-2020, Colin H.: 2017-2020, Jesse B: 2017-2019, Mathew M.: 2020-2021, Avery: 2017-2019, Cole: 2020-2021, Axil: 2019-2020, Kai S.: 2016-2017, Jojo G: 2017, Will B: 2014-2017, Cameron: 2016-2017, Sam B: 2015, Abe B: 2017, Felix: 2016-2018 and of course Bob, Megan, and Joe for supporting our endeavors and nurturing our ability to reflect .
Futurum tam splendidum est, ocularia solaria induere debeo,
All the best,
Guy Gendell
10.1.25
Dear Reader,
The labs are moving along nicely we have a new member! Dash F. will be joining the INSIGHT lab! Dash will primarily help advance our bioinformatics projects forward through the view of (mostly) non AI emerging technologies. At the risk of my journal turning into a Browser Review blog, I dowloaded Fellou an Agentic AI Browser for a project we will talk more about more next week. Continued discussions into the discussion of the Generative AI lab with my techs. WISRD also had a social it was wonderful and unique from all previous socials due to the new presentation format. I have continued discussion with relevant parties on the future of XR in WISRD. I also participated in the training test the RECON lab did on Monday night and that was very fun, if tiring.
Until next time, per aspera ad astra
All the best,
Guy Gendell

9.26.25
Dear Reader,
I have been as you must understand very busy. First and most excitingly the Generative AI group is welcoming two new members, Austin S and Leo D! With this increased participation in the group we will be able to conduct a wider range of more in depth research within a shorter time span. This will be crucial for continuing both our long term and more short term projects (e.g. the quick investigations of new flashy OSS models that come out from time to time). Our new project we are rolling out this year is regarding the new field of Generative Engine Optimisation (GEO) also known as AI Optimization (AIO) in websites. We will discuss more over the coming weeks but for now we will say that the new project will focus on the behavior of model linked scrapers on websites and how best to regulate them. Other than that we will likely be continuing our small scale research into adolescent use of AI and possibly continue incentive testing within INSIGHT. Also it should be noted that over the past weeks myself and the new Lab techs of the AI group have together completed several games of testing and skill such as mapping every possible permutation of the hand game chopsticks. Which while a simple game is a great introduction to primitive game theory. As promised Above the photo of the generative embedded model from earlier this month. Finally I have been given access to Perplexity’s Comet Browser and I must say though for now it will not be my default the incredible ability and flexibility of the models and agent sytems are incredible, especially compared to competitors like DIA, Pumpkin or even Meteor.
All the best,
Guy Gendell
9.4.25
Dear Reader,
Over the past week or so I have been rebuilding or resetting up many interesting opportunities for the generative AI group as well as other groups and/or projects that I may be a part of. I am excited it does appear that this year generative AI group as well as the Bioinformatics group may gain several new members which will be incredibly exciting. I’ve spent the past few weeks getting to know them. Who exactly that is will become clear as of next week. I can say that some of them have been engaging with me on a small team building exercise of sorts using Teachable Machine from Google to build embedded models to get a better understanding of ML. In this case we are just building an embedded model to recognize the number of digits the occupant of the frame was holding up. This rendered mixed results primarily due to insufficient and lower quality data sources. However I will give my new colleagues space to give their input on the matter and may provide a more detailed report depending on our next course of action. The lab appears to be off to a good start, if a slow one, however, given the increased manpower and resources granted to us this year and proliferation of new tools and methods for study, I believe this to be an auspicious start to the year and cannot wait to share more in due course
Note: Just before I was about to publish this, news broke that The Browser Company of New York, makers of Arc and Dia browser(s) had agreed to be acquired by Atlassian. This represents one of the largest consumer facing AI company acquisitions this decade. As an avid fan of BCNY I wish them all the best and hope that are able to continue their mission of making web browsing more accessible and personal. I have in the past had my issues with both BCNY and Atlassian, however I am excited for this new chapter in their history and I hope this acquisition does not preclude the consumer from access to these incredible tools.
Best,
Guy Gendell